
AI大模型全栈工程师实战培训
浏览:1055次 作者:小编1. 培训背景
2025年初,DeepSeek-R1模型的发布在全球范围内引发广泛关注,其在数学、代码、自然语言推理等任务上性能比肩OpenAI o1正式版,众多组织纷纷探索大模型与人工智能的落地实践。基于此,北京某工业软件行业领军企业特邀中培IT学院入企举办了“AI大模型全栈工程师实战训练营”,旨在提升公司产品智能化水平,增强各部门运用大模型及人工智能技术解决客户实际场景问题的能力,深化培养AI领域技术人才。
2. 培训大纲
章节 | 主要内容 | 细分知识点 |
第一节 主流大模型应用介绍和模型间的商业集成 | 典型大模型比较 | 1. GPT-4(OpenAI) |
大模型整体技术阐述 | 基于 Transformer 架构、支持复杂上下文理解、大模型的量化压缩 | |
GPT-4 相关 | 多模态能力(文本、图像输入)、逻辑推理、长文本生成;应用场景建议:对话系统、内容创作、数据分析、教育 | |
DeepSeek 相关 | 数学、中文问答、CoT、代码生成等方向的 SOTA 做法,长上下文优化;MoE 架构在 R1、V3 模型上的对比技术亮点;应用场景建议:一般性问答、金融数据分析、科研计算、教育解题 | |
商业集成方案 | DeepSeek 与火山 Coze 的商用集成方案 | |
第二节 大模型技术对比和主流大模型选型 | 模型选择 | 1. Deepseek-R1 (7B/67B):中文领域表现 SOTA,支持长上下文推理 |
基础环境搭建实操 | 硬件要求:至少 24GB 显存(如 RTX 3090/A10) + 64GB 内存 | |
第三节 大模型办公效率提升和提示词 Prompt 技巧 | DeepSeek应用相关 | AI工具对个人与企业影响;DeepSeek 与 Llama3、Qwen 的对比;DeepSeek 网页版与本地版功能对比;7B 小模型与 32B 模型功能对比;DeepSeek 角色扮演,打造不同领域的专属 AI 顾问 |
PPT中AI智能应用 | AI自动排版、AI 自动搜图、DeepSeek 辅助 PPT 创意构思、DeepSeek 融合专业PPT应用工具、DeepSeek关联PPT智能插件应用 | |
Excel中的AI智能数据魔法 | AI 自动分析、格式化;AI 自动图表、透视表;DeepSeek 辅助 Excel 深度数据分析;DeepSeek 函数编写 “神助攻”;DeepSeek 编写 VBA 代码;工作表数据拆分与合并操作 | |
创意与文档处理 | DeepSeek 作为创意枯竭时的灵感源泉(营销文案、工作报告、创意写作生成案例);DeepSeek 快速精准提炼文档信息;DeepSeek 助力文档智能纠错与优化建议;DeepSeek 助力学术论文撰写 | |
第四节 本地大模型私有化部署 | Deepseek-R1 蒸馏版的部署实操 | 模型获取:通过 HuggingFace 官方仓库申请权限,下载 safetensors 格式权重 |
Deepseek-R1 671B 满血版的部署流程 | 模型获取:从HuggingFace/Modelscope/github 下载参数 | |
Llama-3-8B 快速部署 | 量化加速:FP8 特点,对比 Deepseek 原论文中量化章节 | |
第五节 大模型微调和模型训练 | Deepseek-R1 领域数据微调 | 数据准备:JSONL 格式,含 instruction/input/output;数据源(财报、券商研报等);关键处理:使用 SentencePiece 重组专业术语 tokenization |
适合微调的业务场景探讨 | 阐述项目中 RAG 模式和 LoRA 模式的选择;探讨微调方案的优势,分析不适合微调的场景 | |
第六节 大模型的蒸馏 | 大模型蒸馏核心内容 | 模型蒸馏的知识迁移;参数量压缩、计算效率提升;教师 - 学生架构;BERT/GPT 到 MobileNet 的蒸馏 |
蒸馏相关技术 | 软标签与硬标签选择;损失函数设计、温度参数;知识蒸馏和特征蒸馏的区别;硬蒸馏与软蒸馏的区别;超参数调优(学习率、温度参数、损失权重等) | |
应用场景与模型 | 思考移动端部署或边缘计算的环境场景;DistilBERT、TinyBERT 等预蒸馏模型;Deepseek 中教师模型的产生机制;Deepseek 使用的蒸馏技术总结 | |
第七节 基于 DeepSeek 私有化代码编程 | 本地化模型部署 | 模型获取与安装:获取私有化模型安装包(权重 + 配置文件) |
开发与服务搭建 | 开发工具本地化集成、IDE 插件适配;Cursor、CodeGPT 等工具配置(模型调用指向 DeepSeek API,禁用云端服务);搭建本地模型服务(RESTful API 或 gRPC) | |
安全与管理 | 离线依赖管理:搭建私有仓库;禁用外部数据传输,关闭开发工具自动更新、云同步功能;对模型文件、代码库加密存储,记录模型调用日志;记录用户操作;确定 DeepSeek 离线更新流程,及时打模型补丁 | |
第八节 知识库建设与自定义知识问答 | 私有数据的文档生成系统全流程实操 | 架构设计: |
基于知识库的问答系统实操 | 关键技术点: | |
第九节 大模型系统优化 | 性能加速方案 | 量化压缩:GPTQ 4bit 量化使模型体积减少 70%,采用 DeepseekV3 提出的 MTP 技术实现 tokens |
监控体系建设 | 业务指标:平均响应时间<2.5s,意图识别准确率>92% |
3. 讲师简历
邹老师
长春工业大学人工智能研究院院长、华东建筑设计研究院研究员、山东交通学院客座教授、南昌航空大学校外硕士生导师、中国软件行业协会专家委员、上海市计划生育科学研究所特聘专家、天津大学创业导师、中国医药教育协会老年运动与健康分会学术委员、《聊城大学学报》编委;完成和在研50多个AI工业项目,广泛应用于能源、医疗、交通、气象、银行等多个领域。
近年来取得的主要荣誉:
v 2017年国土资源科学技术一等奖,全国重要矿产资源潜力评价,国土资源部;
v 2018 年山东省优秀科技工作者,山东省科学技术协会;
v 2018年11月一种基于深度学习的早期肺癌检测分类一体化设备与系统,济南计算机科学技术奖评审委员会,二等奖;
v 2018年11月 基于大数据技术的渔商船碰撞预警系统,山东省科学技术协会,三等奖;
v 2019年1月 关于构建山东省海事大数据共享生态圈的建议,二等奖,山东省科学技术协会;
v 2019年1月,被聘为南昌航空大学双师型教师
v 2019年1月“北控杯”人体目标智能识别挑战赛,第三名,中国航天科工集团第四研究院十七所;
v 2019年6月,山东交通学院海事大数据与智能航运联合实验室获得威海市重点实验室;
v 2019年6月被聘为山东交通学院客座教授;
v 入选2021年紫金山英才·江北计划高层次创新创业人才项目入选人才;
v 入选2023年度吴江经济技术开发区崇本科技领军人才。
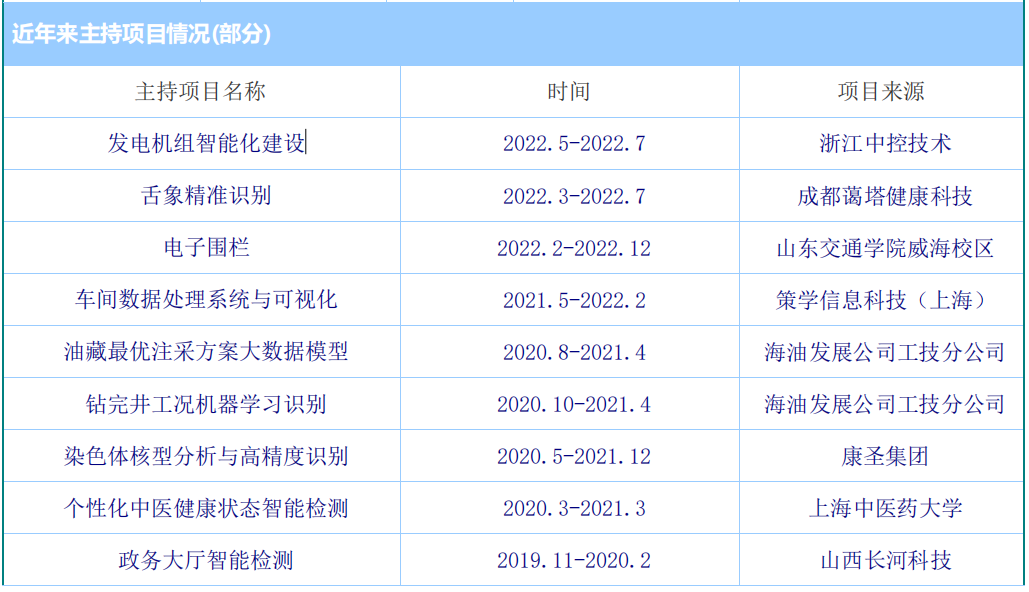
近年来主持项目情况(部分):

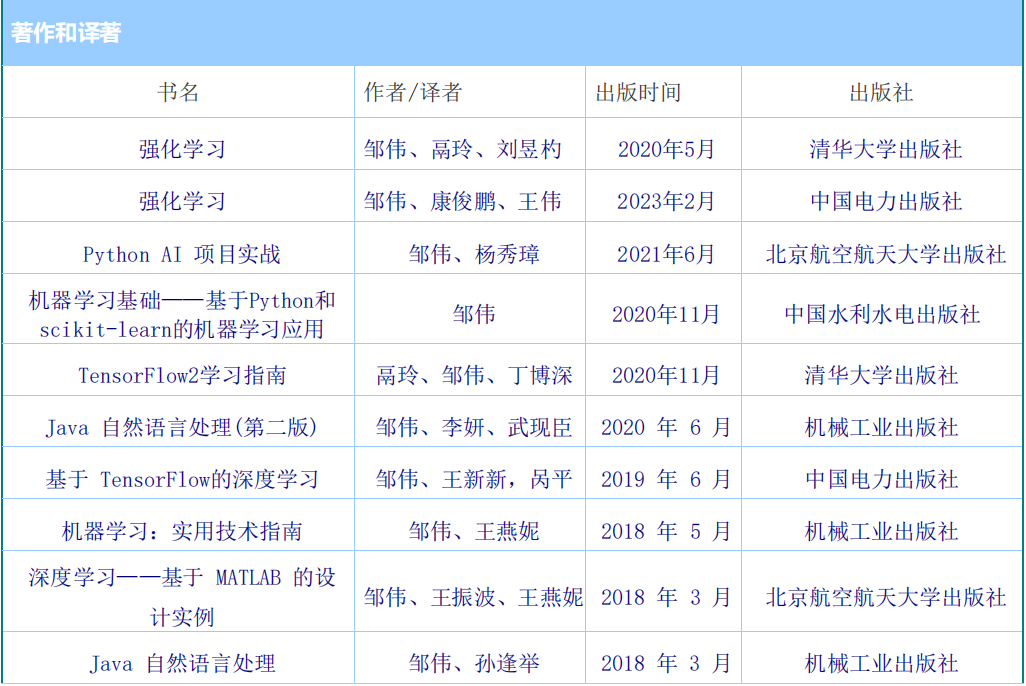
著作和译著:
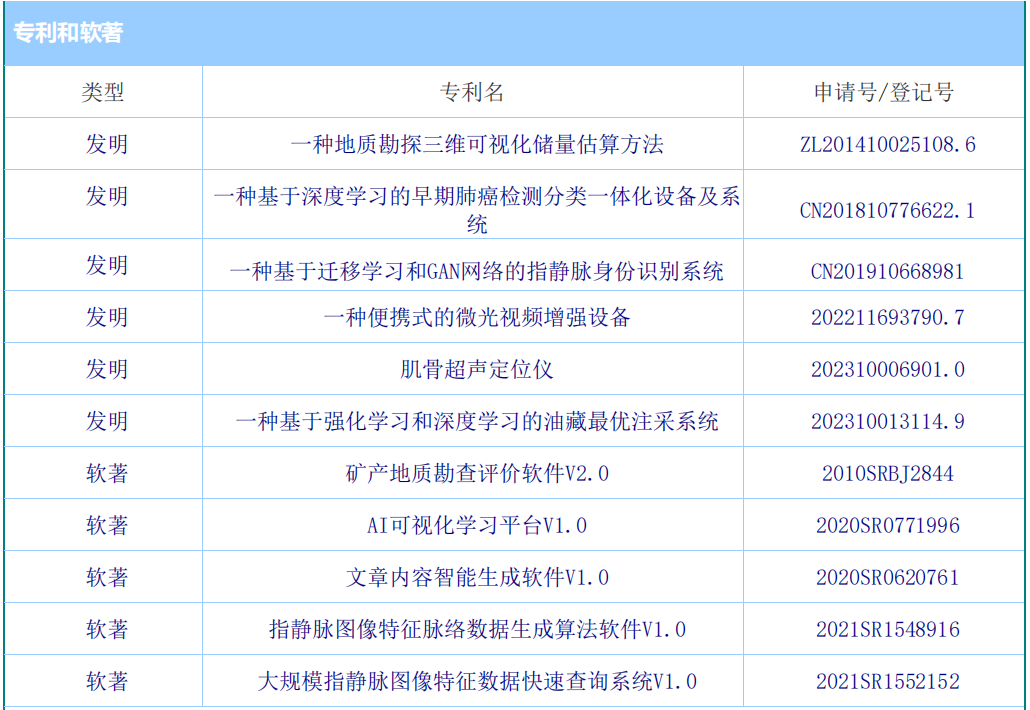
专利和软著:
4. 培训过程
培训于5月22-24日开展,为期三天,共有研发中心技术部的50名技术骨干参加了此次培训。
理论讲解环节,邹伟老师结合DeepSeek等模型的技术原理与行业应用案例,深入剖析大模型核心知识。

案例教学中,以金融数据分析、医疗文档处理等实际场景为例,展示大模型的落地应用。

实操环节,每5人一组,配备RTX4090服务器,学员在真实实验环境中进行模型部署、微调、蒸馏等操作。

互动环节采用破冰起航、分组PK等形式,学员下课积极与老师沟通提问,认真完成服务器实操作业,现场学习氛围浓厚。
5. 培训特色
多样化教学活动:穿插破冰起航、提问互动、分组PK等中培特色教学活动,充分调动学员参与度。
实战化实验环境:全程提供实验环境,每小组配备高性能服务器,让学员在实践中掌握技能。
针对性内容设计:根据工业软件行业需求,结合理论、案例与实操,满足客户提升智能化水平的需求。
6. 培训收益
实战技能提升:学员掌握大模型部署、微调、蒸馏等关键技术,提升实战能力。
解决问题能力:通过综合实验内容,培养学员解决实际问题的能力和团队协作能力。
办公效率提升:学员学会运用大模型提升办公效率,如在PPT、Excel中的智能应用。
AI人才培养:为企业深化培养AI领域技术人才,助力提升产品智能化水平。
7. 培训总结
本次“AI大模型全栈工程师实战训练营”取得了圆满成功。学员们纷纷表示,通过培训不仅掌握了AI大模型的核心技术与应用方法,还结识了一群志同道合的伙伴,为未来的职业发展开辟了新的道路。企业也对此次培训给予了高度评价,认为培训内容贴合实际需求,对提升公司产品的智能化水平具有重要意义。
 AI大模型
AI大模型
- 标签: AI大模型 全栈工程师
-
上篇: 电力行业人工智能与大模型实践培训
下篇: 中油集团某公司软件工程造价师培训

